
We’ll discuss here the top 3 best open-source LLM or Large Language Models.
A language model is similar to a computer program that can understand native human languages like English. To understand the language better, large language models are built using advanced techniques and trained on large contexts of data.
Let’s imagine a library filled with lots of books. It’s obvious that the more books you read, the more you get to know about it and the language. A large language model works in a similar way. It browse through large text data from the internet, books, articles, and more, to better understand how the language works.
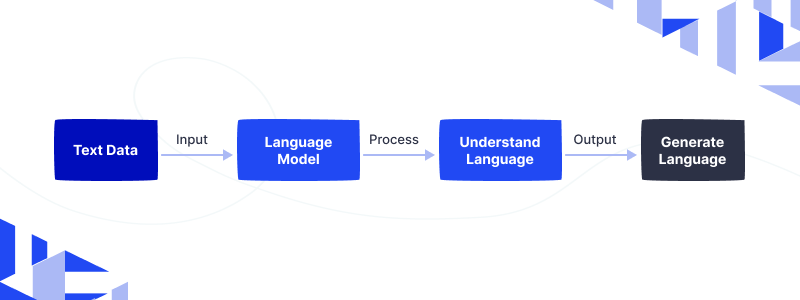
Text data is given to train the model and understand the language better. After thorough learning, the model can generate new language and even write content.
The more data the model has to train on, the better it can understand and generate language. This is what makes LLMs so powerful.
Top 3 Best Open Source LLM
Open-source LLMs are made available to the public for free, without restricting them with proprietary rights. Let’s have a look at the top 3 best open source LLM in recent years.
GPT-3 LLM
GPT-3 (Generative Pre-trained Transformer 3) is an artificial intelligence language model that uses a deep learning technique called a transformer. It’s designed to analyze text and generate human-like language responses to prompts.
Architecture
GPT-3 can be seen as a series of layers, where each layer consists of multiple smaller components called “neurons”. There’s an input layer at the bottom of the architecture that receives text as input.
The text is then passed through a series of hidden layers, each of which analyzes the input and extracts information from it. The output layer generates a response to the input text.
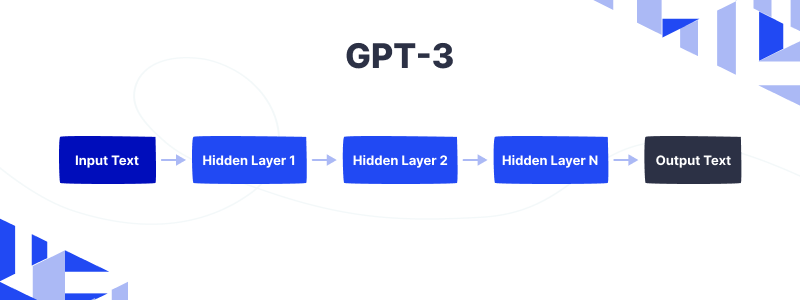
Each hidden layer is made up of multiple “attention heads” that help the model understand the relationships between different parts of the input text. As a result, GPT-3 can generate coherent, contextually relevant responses to complex questions and tasks.
BERT LLM
BERT, or Bidirectional Encoder Representations from Transformers, is a state-of-the-art deep learning model used for natural language processing (NLP) tasks such as question answering, sentiment analysis, and text classification.
Architecture
The input sequence is a sentence or paragraph that is tokenized into individual words or sub-words. These tokens are then converted into embeddings, which are numerical representations of the words.
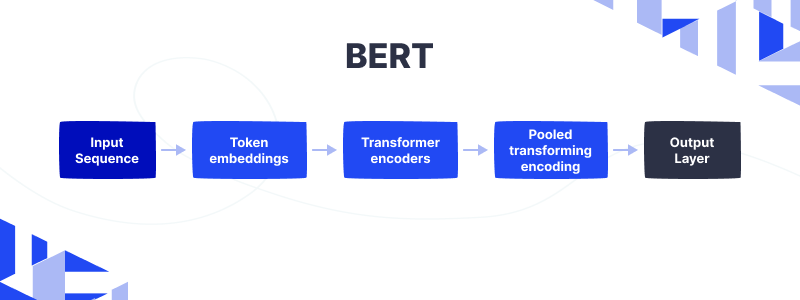
The Transformer encoders analyze the embeddings and learn the relationships between the words in the sentence. The Pooled transformer encoding aggregates the outputs of the Transformer encoders to produce a single vector that represents the entire input sequence.
The final predictions or classification of the input sequence based on the task it has been fine-tuned for are produced by the output layer in the end.
RoBERTa LLM
Developed by Facebook, RoBERTa is an improved version of BERT . It is a type of natural language processing (NLP) model that is based on BERT, but with a few improvements. The name RoBERTa stands for “Robustly Optimized BERT approach”.
Like BERT, RoBERTa is also a Transformer-based model that uses a pre-training technique to understand language better.
The way experts pre-trained BERT and RoBERTa differs in their main aspects. Compared to BERT, RoBERTa is trained for a longer time and on a larger corpus of text data.
This means that RoBERTa has a better understanding of language and can perform better on various NLP tasks.
Architecture
Experts tokenize the input sequence, which is a sentence or paragraph, into individual words or sub-words. They then convert these tokens into embeddings, which are numerical representations of the words.
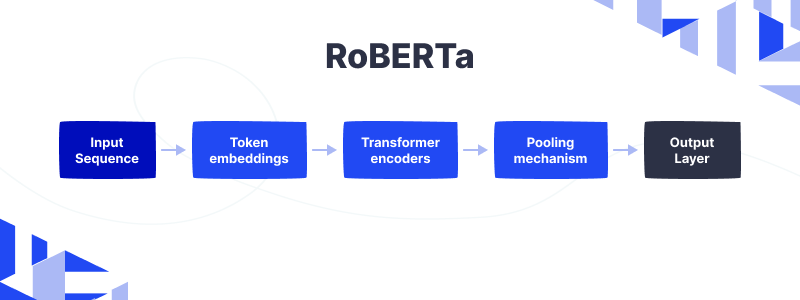
The Transformer encoders analyze the embeddings and learn the relationships between the words in the sentence. The main improvement of RoBERTa is the way it pre-trains the Transformer encoders. RoBERTa uses dynamic masking and removes the next sentence prediction task used in BERT.
The dynamic masking randomly masks out different spans of text in each training epoch, so the model learns to generalize better to different sentence structures. Removing the next sentence prediction task also helps the model to learn better sentence representations.
The pooling mechanism aggregates the outputs of the Transformer encoders to produce a single vector that represents the entire input sequence.
In conclusion, open source language models are becoming increasingly popular due to their ability to understand and process natural language. People widely use GPT-3, BERT, and RoBERTa as examples of the best open source LLM available today.
With the increasing amount of text data available, we can expect to see further advancements and improvements in these models in the future. Let us know your thoughts on comments.



1 comments