There are many myths and misconceptions about HTTP caches. In this article, we’ll dispel some of the most common ones.
Common myths about HTTP caches
Let’s discuss in detail some of the common ones
Browsers only cache resources
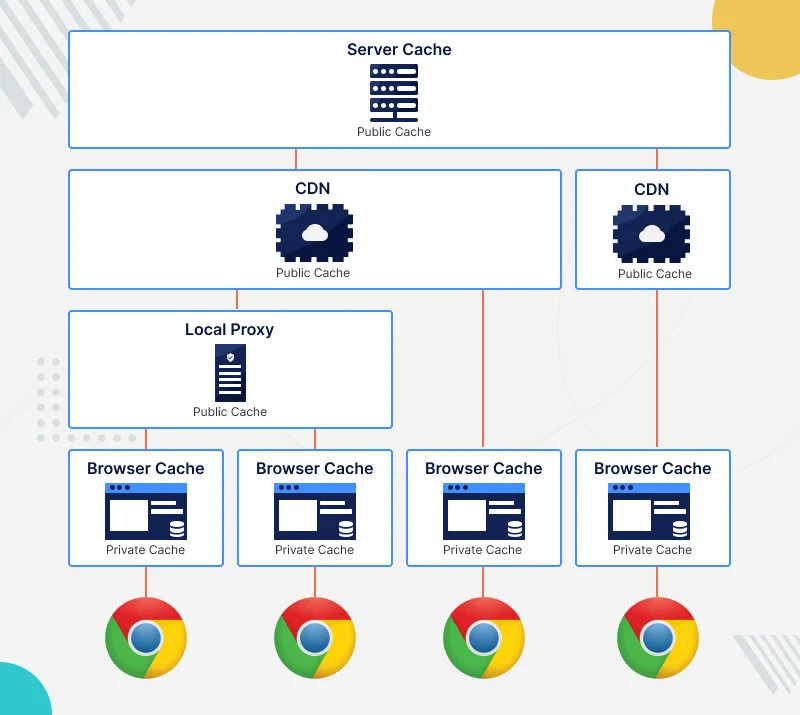
HTTP caches are often misunderstood. There are multiple layers of cache, each with a different purpose. Some caches are dedicated to a single user, while others serve multiple users. Some caches are controlled by the server, while others are controlled by intermediaries or the user themselves.
Browser caches.
A single user owns and uses these caches, which are integrated into their web browser. As a result, performance is improved because the same response is not fetched more than once.
Local proxy cache
A local proxy is a software that acts as an intermediary between a user and the internet. It can be installed by the user, or managed by intermediaries such as their company, organization, or internet provider. Local proxies often cache a single response for multiple users, which constitutes a “public” cache. Local proxies have multiple roles.
Origin server cache / CDN
Origin servers cache content so that users won’t be forced to hit the actual server every time they load a specific request. A CDN does something more complex, but similar: it serves up requests quickly for customers around the world by assigning them to a data centre closest to those users.
HTTPS resources cannot be cached by intermediaries due to SSL
A proxy is often installed on a company employee’s workstation. Web browsers are configured to trust the local proxy’s certificates, and it serves as an intermediary for HTTPS connections. Many users use this locally-configured proxy to “share a metered connection,” or for “virus inspection purposes”.
The user may not realize that the local cache also stores traffic passing through it such as TLS conversations encrypted with certificates delegated to trusted third parties. Ultimately, some HTTPS resources may be cached by these local proxies when they are downloaded by employees using their corporate credentials.



Be the first to comment.